So far, we have focused on n8n’s core functionalities and building workflows within its interface. In this recitation, we will connect n8n to Lovable to add a frontend to turn our processes into a complete, end-to-end product.
You’ll Need…
- Lovable account
- Google Sheets connection
- OpenAI connection
- Google Sheet with the following column names:
| session_id | text | type | company | jobTitle | jobDescription | |
|---|---|---|---|---|---|---|
- Optional: SerpAPI account
You can watch a video recording of the recitation here:
Learning Objectives
- Explain what a webhook is and how webhooks work in n8n.
- Describe how to connect n8n to a front-end tool such as Lovable (or another app that can send HTTP requests).
HTTP Requests and Webhooks
Previously, we mentioned the HTTP Request node as a way to connect to other services/APIs. We now introduce the Webhook, which serves a complementary role.
An HTTP request let you send information from n8n to other services. While you might receive information back, this interaction is initiated by n8n. Many of the nodes we have already used (such as adding rows to a Google Sheet or calling the OpenAI API) are HTTP requests that have a nice wrapper to make them easier to use.
A webhook lets you receive information from other services. This interaction is initiated by these external services, not n8n. For example, some of the trigger nodes (like triggering a workflow when we receive an email) would be a webhook. In our case, we will send a message on a webpage, which will trigger our workflow.
Both nodes have many methods which allow them to send/receive different types of information. This is beyond the scope of the class, but you can read about these here.
In n8n, a Webhook node:
- Has a method (
GET,POST, etc.).- Methods indicate the purpose of the request and what should be expected for a successful request. In our case, we will use
POSTsince we want to send information back and forth between the two
- Methods indicate the purpose of the request and what should be expected for a successful request. In our case, we will use
- Has a path (e.g.,
"39706c09-...").- This is randomly generated and matches the end of the URL
-
Exposes a derived URL like:
https://<your-n8n-instance>/webhook/<path>
n8n provides you with a test URL, as well as a production URL which you would use for the actual product.
When a request hits this URL:
- The request body appears on
$json(for JSON payloads). - Query parameters appear on
$query. - The workflow starts running from that Webhook node.
We will choose the Respond option called Using 'Respond to Webhook' node so that we have more control over when we return information.
**Important for security:**
Never publish your real webhook URLs. Anyone could send information to this URL and potentially access your information from your workflows.
Part 1: ChatGPT Clone
As a basic example, we will make something that looks like a chatbot, consisting of a front-end in Lovable and a back-end in n8n. Let’s get started!
We will walk through the steps of this simple n8n workflow, but you can also copy and paste it here:
Show code (140 lines)
{
"nodes": [
{
"parameters": {
"promptType": "define",
"text": "={{ $json.body.text }}",
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 3.1,
"position": [
976,
128
],
"id": "3cced00c-f094-40ba-bb0f-741b2e06a749",
"name": "AI Agent"
},
{
"parameters": {
"sessionIdType": "customKey",
"sessionKey": "={{ $json.body.sessionId }}"
},
"type": "@n8n/n8n-nodes-langchain.memoryBufferWindow",
"typeVersion": 1.3,
"position": [
992,
336
],
"id": "b0ba5b07-1853-4fa1-9681-37fc3ea29f41",
"name": "Simple Memory"
},
{
"parameters": {
"model": {
"__rl": true,
"mode": "list",
"value": "gpt-4.1-mini"
},
"builtInTools": {},
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatOpenAi",
"typeVersion": 1.3,
"position": [
848,
336
],
"id": "f1fa518f-03b1-4c80-98a7-4bffcc4f580f",
"name": "OpenAI Chat Model",
"credentials": {
"openAiApi": {
"id": "ng8YPN3U1fTEiF8P",
"name": "AIML901 OpenAI account"
}
}
},
{
"parameters": {
"respondWith": "json",
"responseBody": "={\n \"output\": \"{{ $json.output }}\",\n \"sessionId\": \"{{ $('Webhook3').item.json.body.sessionId }}\"\n}",
"options": {}
},
"type": "n8n-nodes-base.respondToWebhook",
"typeVersion": 1.5,
"position": [
1328,
128
],
"id": "b63f4430-dd40-4753-8928-e742228b156d",
"name": "Respond to Webhook"
},
{
"parameters": {
"httpMethod": "POST",
"path": "0de2a342-f8ed-4e0c-b642-400b083be0a7",
"options": {}
},
"type": "n8n-nodes-base.webhook",
"typeVersion": 2.1,
"position": [
736,
128
],
"id": "26755fd6-ca99-4927-b6cb-182a73d0e3c7",
"name": "Webhook",
"webhookId": "0de2a342-f8ed-4e0c-b642-400b083be0a7"
}
],
"connections": {
"AI Agent": {
"main": [
[
{
"node": "Respond to Webhook",
"type": "main",
"index": 0
}
]
]
},
"Simple Memory": {
"ai_memory": [
[
{
"node": "AI Agent",
"type": "ai_memory",
"index": 0
}
]
]
},
"OpenAI Chat Model": {
"ai_languageModel": [
[
{
"node": "AI Agent",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Webhook": {
"main": [
[
{
"node": "AI Agent",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "dc2f41b0f3697394e32470f5727b760961a15df0a6ed2f8c99e372996569754a"
}
}
**Important for security:**
If you copy the above workflow, you should delete and remake the
Webhooknode to generate a new URL, since this one has been posted online.
Step 1: Webhook
- Add node:
Webhook- This lets us receive information sent from Lovable. The
Test URLorProduction URL(depending on which one you choose) indicates where Lovable will send information that n8n will then listen for.
- This lets us receive information sent from Lovable. The
-
HTTP Method: ChoosePOST. This is the most common method we will use, since it is the standard way to send data from one system to another. -
Path: We can leave this, but we can also change it. Note that it changes the URL, as well. -
Authentication: We will leave this asNone, but can use this to verify that the service calling the webhook is one that you recognize. -
Respond: We need our AI Agent to first create a response, so we chooseUsing 'Respond to Webhook' Node. - You can look at the options for how to deal with sending files (binary data), among other things.
- What it does: This lets us receive messages from Lovable.
For now, we use the Test URL, but we would switch this to Production URL for deployment.
Step 2: AI Agent
When Lovable sends information to our n8n webhook, it does so in a JSON format. We can actually specify what information we want to send, which we will talk about more in Step 4. In this case, we assume that we pass a key called body which is a JSON object with keys text (representing the message from the user) and sessionId (representing the whole conversation).
Just like in Recitation 1, we want to make sure that our agent remembers our conversation. We will do this by having Lovable generate a sessionId every time that a user visits the website and then we will pass this back and forth between Lovable and n8n, using it to remember which messages to reference.
- Add node:
AI Agent -
Source for Prompt: ChooseDefine below. -
Prompt (User Message): Use the following. In our Lovable prompt, we will specify how information will be sent from Lovable.
{{ $json.body.text }}
- We can always add a system prompt or some tools!
- Add a
Chat ModelandSimple Memory. InSimple Memory:-
Session ID: ChooseDefine below -
Key:
-
{{ $json.body.sessionId }}
Step 3: Webhook Response
By default, the AI Agent node returns a single key, called output. We then want to send that back to Lovable, along with the sessionId so that we can continue to pass it back and forth.
- Add node:
Respond to Webhook -
Respond With: ChooseJSON -
Response Body:
{
"output": "{{ JSON.stringify($json.output).slice(1, -1) }}",
"sessionId": "{{ $('Webhook').item.json.body.sessionId }}"
}
Note that we need to put JSON expressions still in quotations to signal that they are strings (words).
Now, we are pretty much set in n8n! If we want to have this workflow constantly listen for anything from Lovable, we need to publish the workflow.
Step 4: Lovable
Now, we need to set up our beautiful front-end! You can do this in many ways, but the important information is that we are making a chatbot with an n8n back-end and that we have certain JSON keys that we will send/receive, along with the method that we will use. Here is the prompt that I used, but feel free to come up with your own:
Make an AI chatbot using n8n as a back-end. You will use the method POST to the URL https://aiml901-martin.app.n8n.cloud/webhook-test/0de2a342-f8ed-4e0c-b642-400b083be0a7 and send a JSON object with keys sessionId and text. You will receive as a response a JSON object with that same key sessionId and output. You will display output. Make this chatbot Northwestern Kellogg purple.
Note that I didn’t even tell it how to handle sessionId. We might want to specify this, just to make sure that it is doing what we want, but it is a good starting point!
Exercises:
- What would we do if we wanted our chatbot to be able to read our email? Note: this is sort of like how different services connect to ChatGPT, Claude, or other LLMs!
- What if we wanted the user to be able to set a system message?
Part 2: Interview Prep Agent
Our running example is an interview coach bot. Our process will be as follows:
- A user fills in a form on a website with:
- Interviewee name
- Company name
- Job title
- Job description
- (Optional) resume upload
- When they submit the form, an AI agent will play the role of the interviewer and ask questions like a custom GPT, but with the added context from the job description. Questions and answers will be logged in a Google Sheet for future reference.
- At the end, the user can click “Analyze conversation”:
- n8n pulls the full conversation from the Google Sheet.
- This is sent to an Analysis Agent, which returns feedback on their performance.
Note that while we could do this all in n8n, most products have a nice frontend. We will make a website in Lovable and then use a webhook to send information back and forth between Lovable and n8n
The Workflow
You can copy and paste the entire workflow here:
Show code (1149 lines)
{
"nodes": [
{
"parameters": {
"promptType": "define",
"text": "=Interviewee Name: {{ $('Initial Form Response').item.json.body.name }}\nCompany Name: {{ $('Initial Form Response').item.json.body.company }}\nJob Title: {{ $('Initial Form Response').item.json.body.jobTitle }}\nJob Description: {{ $('Initial Form Response').item.json.body.jobDescription }}\nResume: {{ $json.text }}",
"options": {
"systemMessage": "You are an interviewer. You work at the company given by the job title, and you are interviewing the user for the role also that is given. Ask questions to determine their fit for the role and understand their experience. Just like an interviewer, you're only going to ask one question at a time; concentrate on focused questions. Your role is to be a good example of what an interview might look like. Available to you is connection to the internet, so you are able to search for the company and gain information on them as well.\n\nImportant note: unless specifically asked for clarification, when asking questions, DO NOT give examples to the interviewee. They should think through the question on their own."
}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 2.2,
"position": [
800,
-96
],
"id": "f3ee0f11-cb90-418e-bdcd-8a157b557175",
"name": "AI Agent"
},
{
"parameters": {
"model": {
"__rl": true,
"value": "gpt-5",
"mode": "list",
"cachedResultName": "gpt-5"
},
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatOpenAi",
"typeVersion": 1.2,
"position": [
880,
144
],
"id": "355aa427-30dd-400a-a286-70a330176d94",
"name": "OpenAI Chat Model",
"credentials": {
"openAiApi": {
"id": "ng8YPN3U1fTEiF8P",
"name": "AIML901 OpenAI account"
}
}
},
{
"parameters": {
"sessionIdType": "customKey",
"sessionKey": "={{ $('Create Session ID').item.json.session_id }}",
"contextWindowLength": 20
},
"type": "@n8n/n8n-nodes-langchain.memoryBufferWindow",
"typeVersion": 1.3,
"position": [
1072,
144
],
"id": "cd9378a0-4907-4d72-b211-33b8ab0c9316",
"name": "Simple Memory"
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.toolSerpApi",
"typeVersion": 1,
"position": [
1248,
144
],
"id": "ed43ae2a-f926-4a4e-a551-e200bb20df5d",
"name": "SerpAPI",
"disabled": true
},
{
"parameters": {
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"id": "e3bd1619-aff7-4bda-91da-705f2c2f0efd",
"leftValue": "={{ $('Initial Form Response').item.binary.resume }}",
"rightValue": "",
"operator": {
"type": "object",
"operation": "exists",
"singleValue": true
}
}
],
"combinator": "and"
},
"options": {}
},
"type": "n8n-nodes-base.if",
"typeVersion": 2.2,
"position": [
-192,
-112
],
"id": "da9aee4f-e6f8-46ba-9418-71245846c033",
"name": "If"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "f08e2fdb-78d8-4052-825a-57581c91424f",
"name": "text",
"value": "No resume included",
"type": "string"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
64,
0
],
"id": "0ecdabb6-8d49-4cff-bccb-a73aa151252b",
"name": "No Resume"
},
{
"parameters": {
"operation": "pdf",
"binaryPropertyName": "resume",
"options": {}
},
"type": "n8n-nodes-base.extractFromFile",
"typeVersion": 1,
"position": [
64,
-208
],
"id": "4d56f2ea-56e3-42db-8313-b8185148c7f7",
"name": "Extract from File"
},
{
"parameters": {
"promptType": "define",
"text": "=Interviewee Response: {{ $('Responding to Questions').item.json.body.message }}",
"options": {
"systemMessage": "You are an interviewer. You work at the company given by the job title, and you are interviewing the user for the role also that is given. Ask questions to determine their fit for the role and understand their experience. Just like an interviewer, you're only going to ask one question at a time; concentrate on focused questions. Your role is to be a good example of what an interview might look like. Available to you is connection to the internet, so you are able to search for the company and gain information on them as well.\n\nImportant note: unless specifically asked for clarification, when asking questions, DO NOT give examples to the interviewee. They should think through the question on their own."
}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 2.2,
"position": [
880,
416
],
"id": "fa09c880-e1b5-4683-8d4f-49cf44589f45",
"name": "AI Agent1"
},
{
"parameters": {
"respondWith": "json",
"responseBody": "={\n \"output\": \"{{ $json.output }}\",\n \"session_id\": \"{{ $('Responding to Questions').item.json.body.session_id }}\"\n}",
"options": {}
},
"type": "n8n-nodes-base.respondToWebhook",
"typeVersion": 1.4,
"position": [
1200,
416
],
"id": "e465ff92-f4cf-408b-92d6-7379ef179340",
"name": "Send Question"
},
{
"parameters": {
"respondWith": "json",
"responseBody": "={\n \"output\": \"{{ $json.output }}\",\n \"session_id\": \"{{ $('Create Session ID').item.json.session_id }}\",\n \"email\": \"{{ $('Initial Form Response').item.json.body.email }}\"\n}",
"options": {}
},
"type": "n8n-nodes-base.respondToWebhook",
"typeVersion": 1.4,
"position": [
1152,
-96
],
"id": "fbacb469-bb9d-4c41-afb8-eba4d6893980",
"name": "Send Initial Question"
},
{
"parameters": {
"content": "## Responding to the form and storing the data",
"height": 544,
"width": 1024
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
-720,
-288
],
"id": "88cfbdc1-ddaf-4d21-b3da-05eda8b8e36a",
"name": "Sticky Note"
},
{
"parameters": {
"content": "## Interview Questions",
"height": 992,
"width": 1328,
"color": 3
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
352,
-160
],
"id": "8543d70b-fe9d-4c9b-840c-c8cc1f295680",
"name": "Sticky Note2"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "e2bef90b-1c27-4e68-953f-5e0bc38f638b",
"name": "session_id",
"value": "={{ $('Initial Form Response').item.json.body.email }}-{{ $now }}",
"type": "string"
}
]
},
"includeOtherFields": true,
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-432,
-112
],
"id": "44ba6ec9-71b2-4664-9122-9349c7c15cac",
"name": "Create Session ID"
},
{
"parameters": {
"operation": "append",
"documentId": {
"__rl": true,
"value": "1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw",
"mode": "list",
"cachedResultName": "Interview Prep",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw/edit?usp=drivesdk"
},
"sheetName": {
"__rl": true,
"value": "gid=0",
"mode": "list",
"cachedResultName": "Interview Sheet",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw/edit#gid=0"
},
"columns": {
"mappingMode": "defineBelow",
"value": {
"session_id": "={{ $('Create Session ID').item.json.session_id }}",
"text": "={{ $('Send Initial Question').item.json.output }}",
"email": "={{ $('Initial Form Response').item.json.body.email }}",
"type": "question",
"company": "={{ $('Initial Form Response').item.json.body.company }}",
"jobTitle": "={{ $('Initial Form Response').item.json.body.jobTitle }}",
"jobDescription": "={{ $('Initial Form Response').item.json.body.jobDescription }}"
},
"matchingColumns": [],
"schema": [
{
"id": "email",
"displayName": "email",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "session_id",
"displayName": "session_id",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "text",
"displayName": "text",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "type",
"displayName": "type",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "company",
"displayName": "company",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true,
"removed": false
},
{
"id": "jobTitle",
"displayName": "jobTitle",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true,
"removed": false
},
{
"id": "jobDescription",
"displayName": "jobDescription",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true,
"removed": false
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {}
},
"type": "n8n-nodes-base.googleSheets",
"typeVersion": 4.7,
"position": [
1440,
-96
],
"id": "d056e70a-2654-4774-b5c9-6c350a3a5739",
"name": "Append row in sheet",
"credentials": {
"googleSheetsOAuth2Api": {
"id": "shJALxJGn2GrowJT",
"name": "Alex Google Sheets"
}
}
},
{
"parameters": {
"operation": "append",
"documentId": {
"__rl": true,
"value": "1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw",
"mode": "list",
"cachedResultName": "Interview Prep",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw/edit?usp=drivesdk"
},
"sheetName": {
"__rl": true,
"value": "gid=0",
"mode": "list",
"cachedResultName": "Interview Sheet",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw/edit#gid=0"
},
"columns": {
"mappingMode": "defineBelow",
"value": {
"session_id": "={{ $json.body.session_id }}",
"text": "={{ $json.body.message }}",
"email": "={{ $json.body.email }}",
"type": "answer"
},
"matchingColumns": [],
"schema": [
{
"id": "email",
"displayName": "email",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "session_id",
"displayName": "session_id",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "text",
"displayName": "text",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "type",
"displayName": "type",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "company",
"displayName": "company",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true,
"removed": true
},
{
"id": "jobTitle",
"displayName": "jobTitle",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true,
"removed": true
},
{
"id": "jobDescription",
"displayName": "jobDescription",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true,
"removed": true
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {}
},
"type": "n8n-nodes-base.googleSheets",
"typeVersion": 4.7,
"position": [
688,
416
],
"id": "84a910ff-2529-4a4f-96ba-21fa684c4302",
"name": "Append row in sheet1",
"credentials": {
"googleSheetsOAuth2Api": {
"id": "shJALxJGn2GrowJT",
"name": "Alex Google Sheets"
}
}
},
{
"parameters": {
"operation": "append",
"documentId": {
"__rl": true,
"value": "1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw",
"mode": "list",
"cachedResultName": "Interview Prep",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw/edit?usp=drivesdk"
},
"sheetName": {
"__rl": true,
"value": "gid=0",
"mode": "list",
"cachedResultName": "Interview Sheet",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw/edit#gid=0"
},
"columns": {
"mappingMode": "defineBelow",
"value": {
"session_id": "={{ $('Responding to Questions').item.json.session_id }}",
"text": "={{ $json.output}}",
"email": "={{ $('Responding to Questions').item.json.body.email }}",
"type": "question"
},
"matchingColumns": [],
"schema": [
{
"id": "email",
"displayName": "email",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "session_id",
"displayName": "session_id",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "text",
"displayName": "text",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "type",
"displayName": "type",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "company",
"displayName": "company",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true,
"removed": true
},
{
"id": "jobTitle",
"displayName": "jobTitle",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true,
"removed": true
},
{
"id": "jobDescription",
"displayName": "jobDescription",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true,
"removed": true
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {}
},
"type": "n8n-nodes-base.googleSheets",
"typeVersion": 4.7,
"position": [
1456,
416
],
"id": "93a6d80a-1d1a-4ec1-929b-039e822ce9f4",
"name": "Append row in sheet2",
"credentials": {
"googleSheetsOAuth2Api": {
"id": "shJALxJGn2GrowJT",
"name": "Alex Google Sheets"
}
}
},
{
"parameters": {
"content": "## Analysis of the conversation",
"height": 464,
"width": 1552,
"color": 5
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
-464,
864
],
"id": "4c96a81e-a85e-4135-8f54-2e6fc7a53e67",
"name": "Sticky Note1"
},
{
"parameters": {
"sessionIdType": "customKey",
"sessionKey": "={{ $('Responding to Questions1').item.json.body.session_id }}",
"contextWindowLength": 20
},
"type": "@n8n/n8n-nodes-langchain.memoryBufferWindow",
"typeVersion": 1.3,
"position": [
976,
688
],
"id": "28b6b9b4-22d5-48ca-ad62-b9a56eea3ea4",
"name": "Simple Memory1"
},
{
"parameters": {
"model": {
"__rl": true,
"value": "gpt-5",
"mode": "list",
"cachedResultName": "gpt-5"
},
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatOpenAi",
"typeVersion": 1.2,
"position": [
800,
688
],
"id": "c2d8912f-b2f3-4cf8-9703-3cfcfb2c582c",
"name": "OpenAI Chat Model1",
"credentials": {
"openAiApi": {
"id": "ng8YPN3U1fTEiF8P",
"name": "AIML901 OpenAI account"
}
}
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.toolSerpApi",
"typeVersion": 1,
"position": [
1152,
688
],
"id": "714b7686-2757-457a-87c2-b1f534bdcb5b",
"name": "SerpAPI1",
"disabled": true
},
{
"parameters": {
"documentId": {
"__rl": true,
"value": "1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw",
"mode": "list",
"cachedResultName": "Interview Prep",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw/edit?usp=drivesdk"
},
"sheetName": {
"__rl": true,
"value": "gid=0",
"mode": "list",
"cachedResultName": "Interview Sheet",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1YsqV1kEYkrtxrsfreaK7KGYIZbk0eIgivmG2KaLpkkw/edit#gid=0"
},
"filtersUI": {
"values": [
{
"lookupColumn": "email",
"lookupValue": "={{ $json.body.email }}"
},
{
"lookupColumn": "session_id",
"lookupValue": "={{ $json.body.session_id }}"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.googleSheets",
"typeVersion": 4.7,
"position": [
96,
928
],
"id": "2662f7bc-7155-4cd9-8a8d-a0344e030f7a",
"name": "Get row(s) in sheet",
"credentials": {
"googleSheetsOAuth2Api": {
"id": "shJALxJGn2GrowJT",
"name": "Alex Google Sheets"
}
}
},
{
"parameters": {
"model": {
"__rl": true,
"value": "gpt-5",
"mode": "list",
"cachedResultName": "gpt-5"
},
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatOpenAi",
"typeVersion": 1.2,
"position": [
512,
1136
],
"id": "48904d7b-1294-49ae-9636-1c14f5bfc43b",
"name": "OpenAI Chat Model2",
"credentials": {
"openAiApi": {
"id": "ng8YPN3U1fTEiF8P",
"name": "AIML901 OpenAI account"
}
}
},
{
"parameters": {
"promptType": "define",
"text": "=Company: {{ $json.company }}\nJob Title: {{ $json.jobTitle }}\nJob Description: {{ $json.jobDescription }}\nConversation: {{ $json.conversation }}",
"options": {
"systemMessage": "You are an expert at interview prep. You are provided with a conversation between an interviewer and an interviewee. Your role is to provide expert-level feedback based on the company, job title, job description, and the responses of the user to help the user prepare for the interview.\n\nIn formulating your response, give critical feedback that can help the user improve. Consider their tone, how they present themselves, and any other factors in their responses."
}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 2.2,
"position": [
512,
928
],
"id": "8db07597-2a60-451e-a9aa-da6201258b0b",
"name": "Analysis Agent"
},
{
"parameters": {
"respondWith": "text",
"responseBody": "={{ $json.output }}",
"options": {}
},
"type": "n8n-nodes-base.respondToWebhook",
"typeVersion": 1.4,
"position": [
848,
928
],
"id": "bfc907bc-c104-4685-9398-749fe1dc7afe",
"name": "Respond to Webhook"
},
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
-336,
1136
],
"id": "eda59813-bf1d-41f1-a959-7312693f9411",
"name": "When clicking ‘Execute workflow’"
},
{
"parameters": {
"mode": "raw",
"jsonOutput": "{\n \"body\": {\n \"email\": \"alexander.jensen1@kellogg.northwestern.edu\",\n \"session_id\": \"alexander.jensen1@kellogg.northwestern.edu-2025-10-20T10:32:58.700-05:00\"\n }\n}\n",
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-160,
1136
],
"id": "67def341-0f42-492b-b25c-c8f4b22a0a80",
"name": "Edit Fields1"
},
{
"parameters": {
"content": "\n\n\n\n# Recitation 5 - End-to-End Products with n8n",
"height": 560,
"width": 768,
"color": 6
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
-464,
272
],
"id": "01611138-76f4-4241-9093-276e07cd02b6",
"name": "Sticky Note6"
},
{
"parameters": {
"httpMethod": "POST",
"path": "4fbf6fdf-e7e8-4f77-8b44-fc53c2b0cbe5",
"responseMode": "responseNode",
"options": {}
},
"type": "n8n-nodes-base.webhook",
"typeVersion": 2.1,
"position": [
-672,
-112
],
"id": "c8bced55-53c9-4909-8909-572f6fa3ffd8",
"name": "Initial Form Response",
"webhookId": "4fbf6fdf-e7e8-4f77-8b44-fc53c2b0cbe5"
},
{
"parameters": {
"httpMethod": "POST",
"path": "e04b66cf-d88e-40a7-91fc-17c9387a81c7",
"responseMode": "responseNode",
"options": {}
},
"type": "n8n-nodes-base.webhook",
"typeVersion": 2.1,
"position": [
432,
416
],
"id": "98592108-b01c-45cc-bee8-5d825cc118f2",
"name": "Responding to Questions",
"webhookId": "e04b66cf-d88e-40a7-91fc-17c9387a81c7"
},
{
"parameters": {
"httpMethod": "POST",
"path": "be22d135-0a2a-497a-af26-f51d290705ae",
"options": {}
},
"type": "n8n-nodes-base.webhook",
"typeVersion": 2.1,
"position": [
-224,
928
],
"id": "d9e0b20d-fc1a-49cb-9333-2a3ae4dd34dc",
"name": "Analysis Webhook",
"webhookId": "be22d135-0a2a-497a-af26-f51d290705ae"
},
{
"parameters": {
"jsCode": "// If your column names are different, tweak the lookups below.\nconst first = items[0]?.json ?? {};\n\nconst company = first.company ?? first.Company ?? '';\nconst jobTitle = first.jobTitle ?? first['Job Title'] ?? '';\nconst jobDescription = first.jobDescription ?? first['Job Description'] ?? '';\n\n// Build the conversation from every row (keeps sheet order)\nconst conversation = items\n .map(i => `${i.json.type}: ${i.json.text}`)\n .join('\\n\\n');\n\n\nreturn [{\n json: {\n conversation: conversation,\n company,\n jobTitle,\n jobDescription\n }\n}];\n"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
304,
928
],
"id": "e75a264b-7462-4096-b541-d2b4713c077f",
"name": "Recreating Transcript"
}
],
"connections": {
"AI Agent": {
"main": [
[
{
"node": "Send Initial Question",
"type": "main",
"index": 0
}
]
]
},
"OpenAI Chat Model": {
"ai_languageModel": [
[
{
"node": "AI Agent",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Simple Memory": {
"ai_memory": [
[
{
"node": "AI Agent",
"type": "ai_memory",
"index": 0
}
]
]
},
"SerpAPI": {
"ai_tool": [
[
{
"node": "AI Agent",
"type": "ai_tool",
"index": 0
}
]
]
},
"If": {
"main": [
[
{
"node": "Extract from File",
"type": "main",
"index": 0
}
],
[
{
"node": "No Resume",
"type": "main",
"index": 0
}
]
]
},
"No Resume": {
"main": [
[
{
"node": "AI Agent",
"type": "main",
"index": 0
}
]
]
},
"Extract from File": {
"main": [
[
{
"node": "AI Agent",
"type": "main",
"index": 0
}
]
]
},
"AI Agent1": {
"main": [
[
{
"node": "Send Question",
"type": "main",
"index": 0
}
]
]
},
"Send Question": {
"main": [
[
{
"node": "Append row in sheet2",
"type": "main",
"index": 0
}
]
]
},
"Send Initial Question": {
"main": [
[
{
"node": "Append row in sheet",
"type": "main",
"index": 0
}
]
]
},
"Create Session ID": {
"main": [
[
{
"node": "If",
"type": "main",
"index": 0
}
]
]
},
"Append row in sheet1": {
"main": [
[
{
"node": "AI Agent1",
"type": "main",
"index": 0
}
]
]
},
"Simple Memory1": {
"ai_memory": [
[
{
"node": "AI Agent1",
"type": "ai_memory",
"index": 0
}
]
]
},
"OpenAI Chat Model1": {
"ai_languageModel": [
[
{
"node": "AI Agent1",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"SerpAPI1": {
"ai_tool": [
[
{
"node": "AI Agent1",
"type": "ai_tool",
"index": 0
}
]
]
},
"Get row(s) in sheet": {
"main": [
[
{
"node": "Recreating Transcript",
"type": "main",
"index": 0
}
]
]
},
"OpenAI Chat Model2": {
"ai_languageModel": [
[
{
"node": "Analysis Agent",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Analysis Agent": {
"main": [
[
{
"node": "Respond to Webhook",
"type": "main",
"index": 0
}
]
]
},
"When clicking ‘Execute workflow’": {
"main": [
[
{
"node": "Edit Fields1",
"type": "main",
"index": 0
}
]
]
},
"Edit Fields1": {
"main": [
[
{
"node": "Get row(s) in sheet",
"type": "main",
"index": 0
}
]
]
},
"Initial Form Response": {
"main": [
[
{
"node": "Create Session ID",
"type": "main",
"index": 0
}
]
]
},
"Responding to Questions": {
"main": [
[
{
"node": "Append row in sheet1",
"type": "main",
"index": 0
}
]
]
},
"Analysis Webhook": {
"main": [
[
{
"node": "Get row(s) in sheet",
"type": "main",
"index": 0
}
]
]
},
"Recreating Transcript": {
"main": [
[
{
"node": "Analysis Agent",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "dc2f41b0f3697394e32470f5727b760961a15df0a6ed2f8c99e372996569754a"
}
}
The URLs shown in the webhooks when you copy and paste are only randomly generated when you create the nodes yourself. As a result, these are not the actual webhook URLs used for the example demonstration, since then anyone who had that URL would be able to send information to it.
This workflow contains several parts:
- The user form and initial question;
- The interview with questions and answers;
- The analysis of the conversation.
Note that because these are three different processes entirely, we set up separate webhooks for each.
Here are several highlights for you to explore:
- The
Extract from Filenode lets you extract text or other information from a document. In our case, this lets us extract the raw text from a resume/CV for our AI agent. - SerpAPI is a way to connect a Google Search tool to your agent. In this case, we might want to give our agent this capability, since it would allow it to gain additional context on the company.
- Note that for each additional response for the interview, we do not include the entirety of the previous conversation in the
Prompt (User Message)field. Instead, we originally create a session ID and use this and theSimple Memorynodes to keep track of the conversation throughout. - In the analysis section, we use a
Codenode that we call “Recreating Transcript” to take the rows from the Google Sheet and process them into a transcript of the conversation.
Connecting to Lovable
While we have slightly less control in Lovable, we are able to prompt it to send information to a webhook. For example, my initial prompt for the website focused entirely on the screen where the user inputs information:
Let's make an interview prep site. I want the theme to be based on Northwestern Kellogg's colors, but keep it sleek. There should be a form where a user can fill out the job title, job description, and then also input their resume as a PDF. This will be sent via a webhook to [ADD YOUR WEBHOOK URL HERE]. You will receive questions from n8n that you will present the user with.
Once they input this, this screen should disappear and it should look more like a purple chatbot where they will have a back-and-forth where you ask questions and they respond.
I then iterated on this, including making some fields (like the resume) optional, added a Company field, and described how I wanted the information returned by the n8n workflow to be presented. This gives us a form that looks like this: 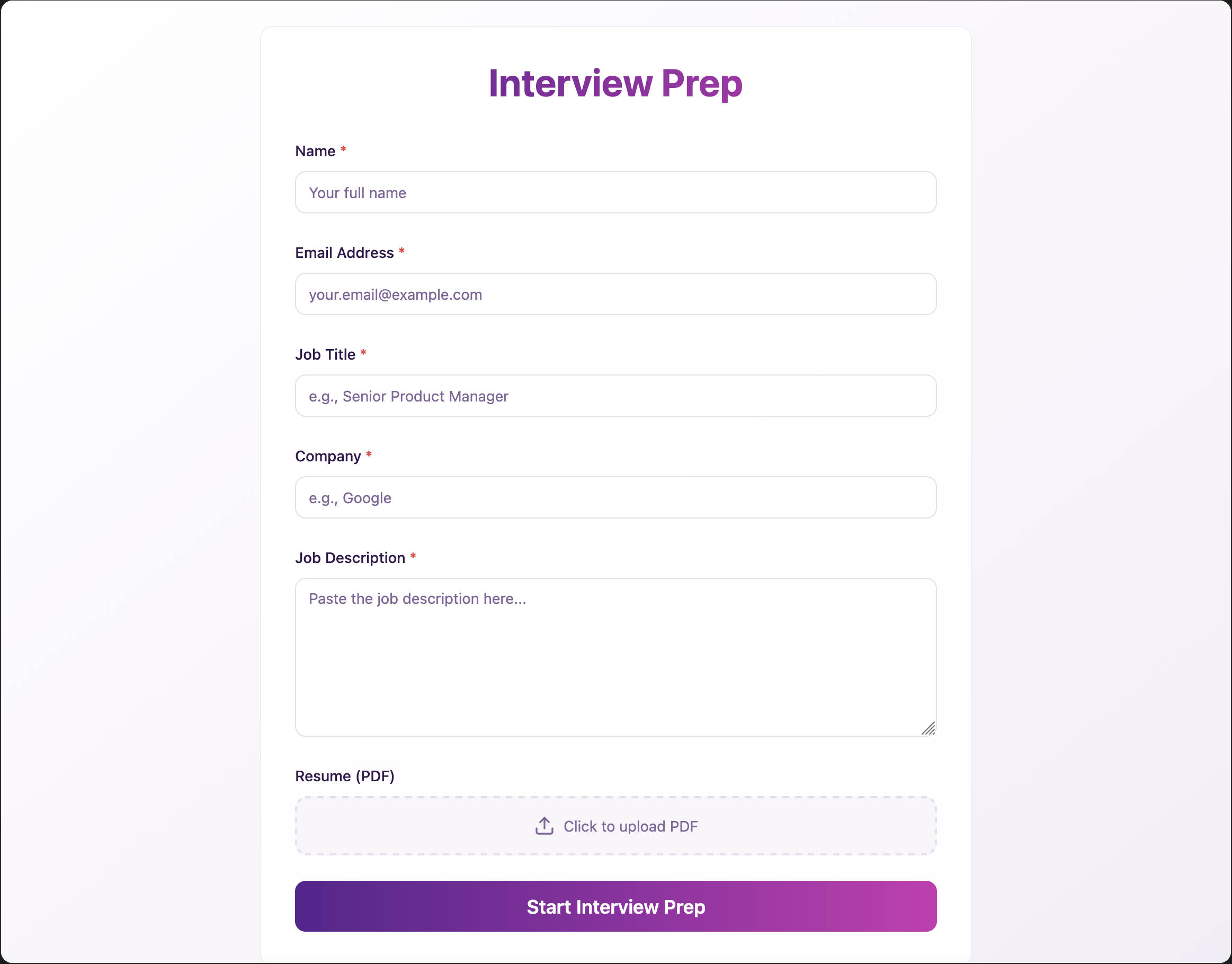
For this first webhook, it will display as the first question on the next screen, where the user holds the conversation: 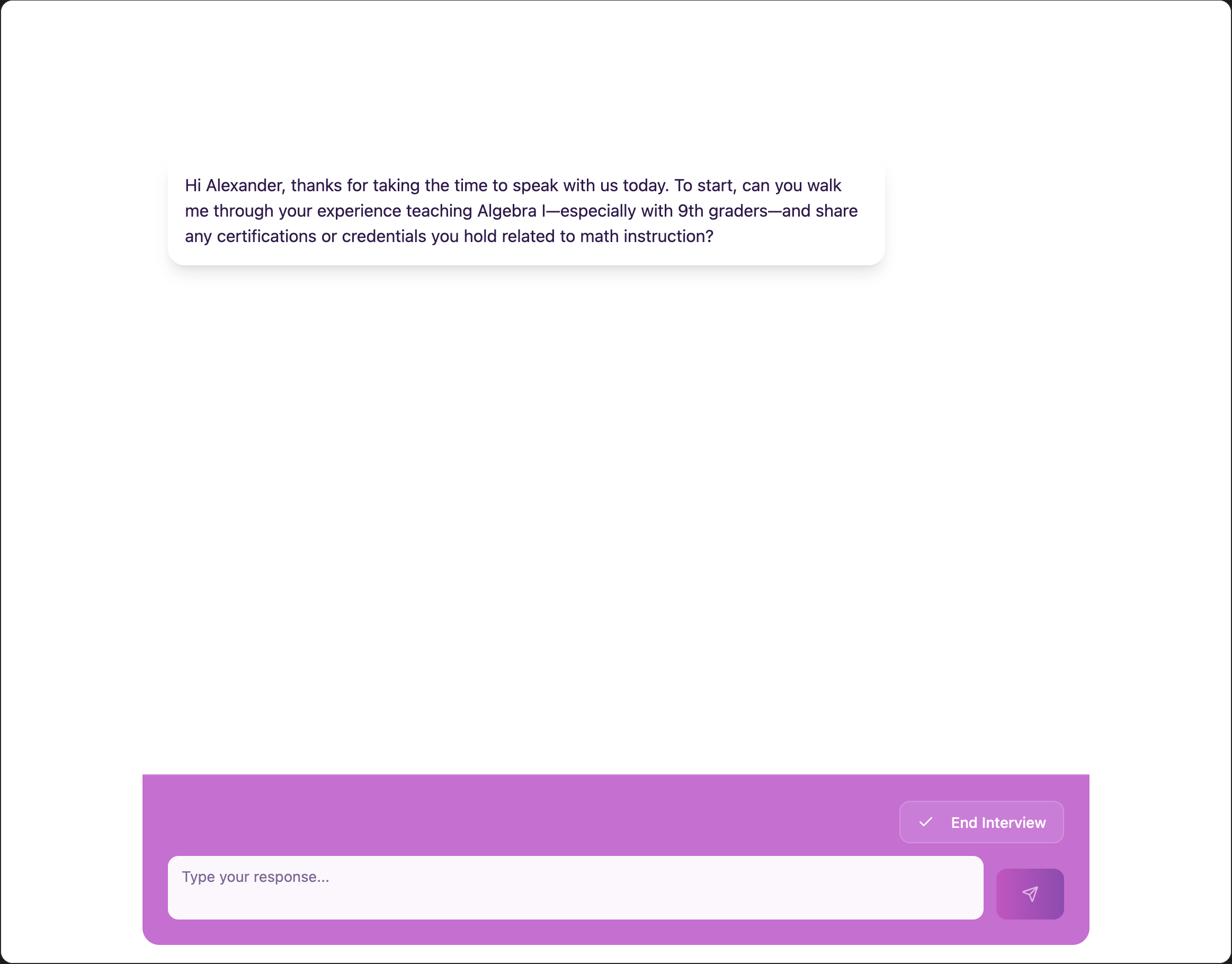
When a user has finished answering the questions that they want to, they can press the “End Interview” button and receive feedback: 
Note that it can take several rounds of iteration in Lovable to get it to display exactly what you want. I recommend using their Chat feature and asking Lovable’s agent questions if information isn’t being passed correctly; it’s very helpful to work through things!